The confusing semi-words, as shown in the image below, that one has to type every now and then while surfing on the web might not read as real words, but in actual they are. They are basically images from the pages of books and are a key reason Google has digitized more than 15 million books since 2004, thanks to reCAPTCHA technology.
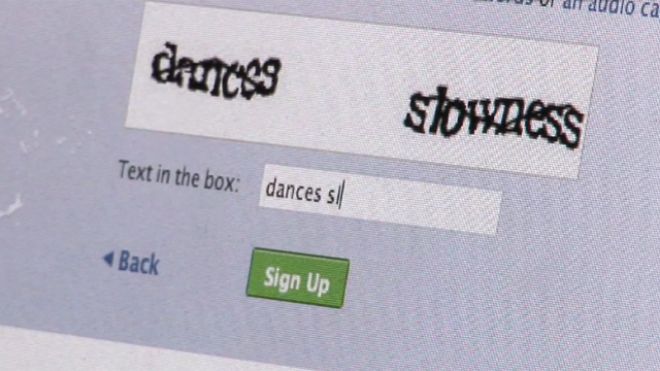
The mastermind behind this reCAPTCHA technology, Luis von Ahn, a computer science professor at Carnegie Mellon University told FoxNews.com, “Humans, at least non-visually impaired humans, have no problem readings these distorted characters. But computer programs can’t do it as well yet.”
The ambiguous bits of books are put by Google that it can’t scan entirely in the reCAPTCHA system and then it’s at the dicretion of humans instead of optical character recognition (OCR) machines to figure out what the words really are. And when the often blurry words are decoded that OCR system of Google is uncertain about, you’re actually helping the huge book project.
Therefore, congrats Web user for being a part-time archivist.